How-to Guide: Utilizing the AIandMe Firewall for Evaluating Prompts
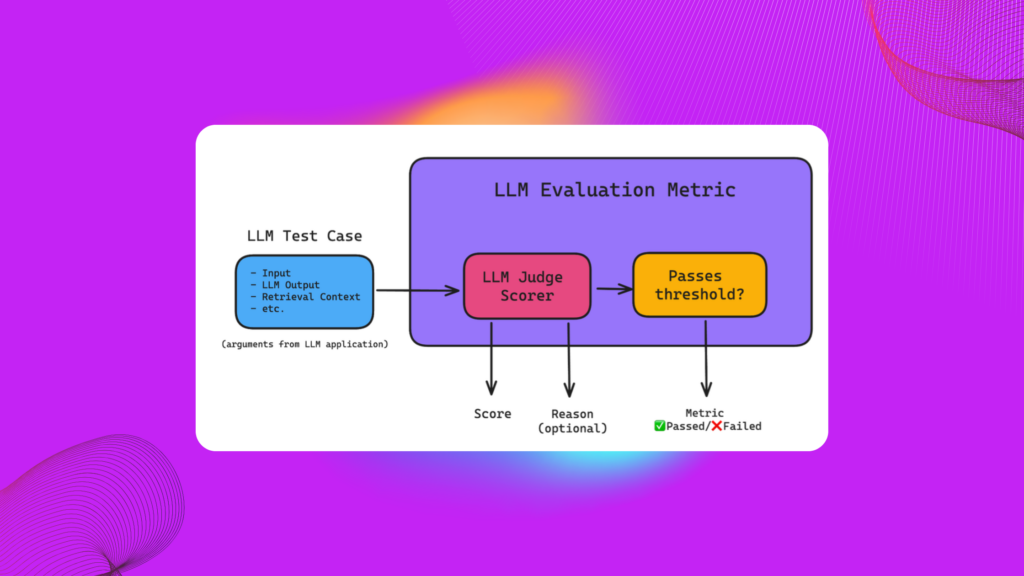
The AIandMe Firewall is a powerful tool designed to evaluate and filter prompts submitted to large language models (LLMs). By ensuring that prompts adhere to defined guidelines, it helps avoid harmful, off-topic, or restricted actions that an AI system should not engage in. In this article, we’ll guide you through the process of utilizing the AIandMe Firewall for prompt evaluation, using both a dataset and manual trials.
LLM as a Judge: The Concept
The concept of LLM as a Judge highlights the role of large language models in evaluating and classifying textual inputs. These models, beyond generating content, can act as decision-makers, assessing inputs for safety, bias, or adherence to specific guidelines. This approach leverages their advanced natural language understanding to provide context-aware judgments, making them invaluable tools in applications like content moderation, AI safety systems, and compliance checks.
The Firewall system follows this principle by utilizing an LLM to analyze prompts dynamically and classify them as safe or unsafe based on predefined criteria. This aligns with the broader concept of LLMs serving as evaluators or judges in automated systems.
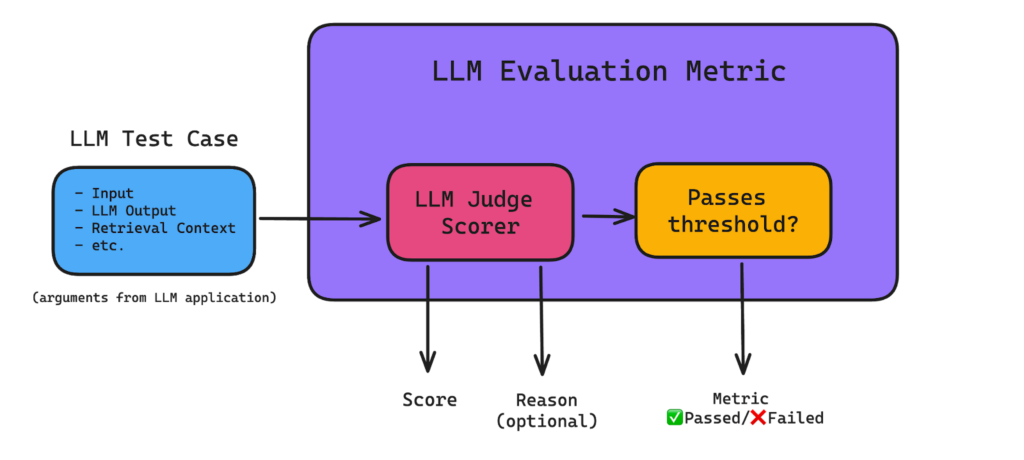
This concept underpins the functionality of the Firewall, ensuring AI-driven safety in content generation and classification systems.
For further exploration of this idea, consider these references:
- Bender, E. M., et al. (2021). “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?”
- Bommasani, R., et al. (2021). “On the Opportunities and Risks of Foundation Models.”
Introduction to AIandMe Firewall
The AIandMe Firewall acts as a safeguard to filter user inputs before they are processed by large language models like GPT-4. This ensures that the AI system behaves in a controlled and safe manner. The Firewall performs a series of checks to determine if the prompt meets specific criteria.
Key Features of the AIandMe Firewall:
- Scope Validation: Ensures that the prompts align with the intended business scope. This helps ensure that the AI is tasked with relevant and appropriate queries.
- Intent Filtering: Filters out any requests that do not match predefined intents. For instance, the model will reject prompts asking it to perform actions outside the intended scope.
- Restricted Action Prevention: Prevents the AI from responding to prompts that ask for prohibited actions, such as generating harmful content or providing sensitive information.
How the Firewall Works:
The Firewall evaluates each prompt and returns a status indicating whether it passed or failed the validation checks. In case of failure, it provides detailed feedback on which part of the prompt violated the guidelines.
In the following sections, we’ll walk through how to use the AIandMe Firewall for both manual and dataset-based evaluations.
Environment Setup and Initialization
To begin utilizing the AIandMe Firewall, you first need to set up the environment with the required variables and initialize the Firewall with a model provider. For this tutorial, we’ll be using Azure OpenAI as our model provider, specifically utilizing the GPT-4o (default) model.
Before proceeding, ensure that you have the necessary credentials for accessing Azure OpenAI services.
import os from aiandme
import FirewallOSS, LLMModelProvider
# Set up environment variables for Azure OpenAI
os.environ["LLM_PROVIDER_ENDPOINT"] = "<your-azure-endpoint>"
os.environ["LLM_PROVIDER_API_KEY"] = "<your-api-key>"
os.environ["LLM_PROVIDER_API_VERSION"] = "<your-api-version"
os.environ["LLM_PROVIDER_MODEL"] = "<your-model>" # Default Value: gpt4-o
# Initialize the Firewall with Azure OpenAI model
fw = FirewallOSS(model_provider=LLMModelProvider.AZURE_OPENAI)In this setup:
- LLM_PROVIDER_ENDPOINT: The endpoint where your Azure OpenAI service is hosted.
- LLM_PROVIDER_API_KEY: The API key for authenticating requests to the Azure OpenAI service.
- LLM_PROVIDER_API_VERSION: The version of the API.
- LLM_PROVIDER_MODEL: Specifies the model we are using.
Before you begin using the AIandMe Firewall notebooks for evaluating prompts, you need to set up a virtual environment and install the necessary dependencies. Here’s how to do it:
Create a Virtual Environment:
If you don’t have Python 3.13 or above, ensure that it’s installed on your system. Then, create and activate a virtual environment:
python3.13 -m venv firewall-env
source firewall-env/bin/activate # On Windows use `firewall-env\Scripts\activate`Install Dependencies:
Once the virtual environment is activated, install the required dependencies using pip:
pip install -r requirements.txtEvaluating the AIandMe Firewall on a Dataset
In this section, we’ll walk through how to evaluate a dataset of prompts using the AIandMe Firewall. The goal is to easily assess whether each prompt adheres to defined safety and scope guidelines.
Step 1: Loading the Dataset with the Correct Format
The first step is to load your dataset, ensuring it follows the correct format. Your dataset should contain two essential columns:
- “Prompt”: The text input to be evaluated.
- “Safe”: The true label indicating whether the prompt is safe (True) or unsafe (False).
Here’s how to load the dataset using pandas:
import pandas as pd
# Function to load the dataset
def load_dataset(file_path):
df = pd.read_csv(file_path)
# Ensure the dataset has the necessary columns
if "Prompt" not in df.columns or "Safe" not in df.columns:
raise ValueError("Dataset must contain 'Prompt' and 'Safe' columns.")
return df
# Load your dataset
dataset = load_dataset("dataset.csv")
Make sure your dataset file is structured correctly before running this function. If you encounter any issues, the code will raise an error, helping you ensure that the data is in the correct format.
Step 2: Evaluating Prompts Easily with the Firewall
Once the dataset is loaded, you can easily evaluate the prompts using the AIandMe Firewall. The firewall will check each prompt and return whether it passes or fails based on predefined guidelines.
The evaluation results will be recorded, including the true label (from your dataset), the predicted label (whether the firewall passed or failed the prompt), and the fail category (if the prompt failed).
Here’s the function to evaluate the prompts:
from aiandme import FirewallOSS, LLMModelProvider
from aiandme.schemas import Logs as LogsSchema
# Initialize Firewall
fw = FirewallOSS(model_provider=LLMModelProvider.AZURE_OPENAI)
# Function to evaluate the dataset
def evaluate_firewall(dataset):
results = []
for index, row in dataset.iterrows():
prompt = row["Prompt"]
true_label = row["Safe"]
try:
# Firewall evaluation
analysis = fw(prompt, log_firewall_results)
# If the prompt passes, set predicted label to True
predicted_label = True if analysis.status else False
# Store evaluation results
results.append({
"Prompt": prompt,
"True Label": true_label,
"Predicted Label": predicted_label,
"Fail Category": analysis.fail_category if not analysis.status else "pass"
})
except Exception as e:
# Handle error if any
results.append({
"Prompt": prompt,
"True Label": true_label,
"Predicted Label": "error",
"Fail Category": str(e)
})
return pd.DataFrame(results)
# Function to log results
def log_firewall_results(log: LogsSchema):
logging.info(f"Log: {log.model_dump()}\n")
# Evaluate the dataset
results_df = evaluate_firewall(dataset)Step 3: Calculating Metrics and Saving Results
Once you’ve evaluated the dataset,important metrics such as accuracy, precision, recall, and F1 score are calculated to assess the firewall’s performance. These metrics help you understand how well the firewall is classifying prompts based on safety and scope. Additionally, a classification report is generated. Finally, the true labels and predictions are saved in a CSV file for future analysis.
By following these steps, you can easily evaluate a large dataset of prompts using the AIandMe Firewall, with the results being saved for later analysis.
Manual Evaluation on Specific Prompts
In this section, we demonstrate how to manually evaluate specific prompts and dynamically test them using the AIandMe Firewall.
1. Evaluate a single prompt manually: The function below allows you to input a prompt dynamically and see how the firewall classifies it—whether it passes or fails, and the corresponding fail category if applicable.
# Function to evaluate a single prompt manually
def evaluate_manual_firewall(prompt):
try:
analysis = fw(prompt, log_firewall_results)
# Determine if the prompt passes the firewall
predicted_label = True if analysis.status else False
result = {
"Prompt": prompt,
"Predicted Label": predicted_label,
"Fail Category": analysis.fail_category if not analysis.status else "pass"
}
logging.info(f"Manual Evaluation Result: {result}")
return result
except Exception as e:
logging.error(f"Error evaluating prompt: {prompt}. Error: {e}")
return {
"Prompt": prompt,
"Predicted Label": "error",
"Fail Category": str(e)
}
2. Dynamic Input and Evaluation: You can now input any prompt you’re curious about, and the firewall will classify it accordingly.
# Main function to handle manual input and evaluate
def main():
logging.info("Enter a prompt to evaluate:")
prompt = input("Prompt: ") # Dynamically input a prompt
logging.info("Evaluating Firewall for manual input...\n")
result = evaluate_manual_firewall(prompt)
if __name__ == "__main__":
main()This allows you to dynamically test any prompt, making it easy to see how the firewall classifies different inputs in real-time.
Experimenting with AIandMe: Zero-Code Project Setup
Setting up a project on the AIandMe platform is straightforward and requires minimal effort. Follow these simple steps:
Project Creation
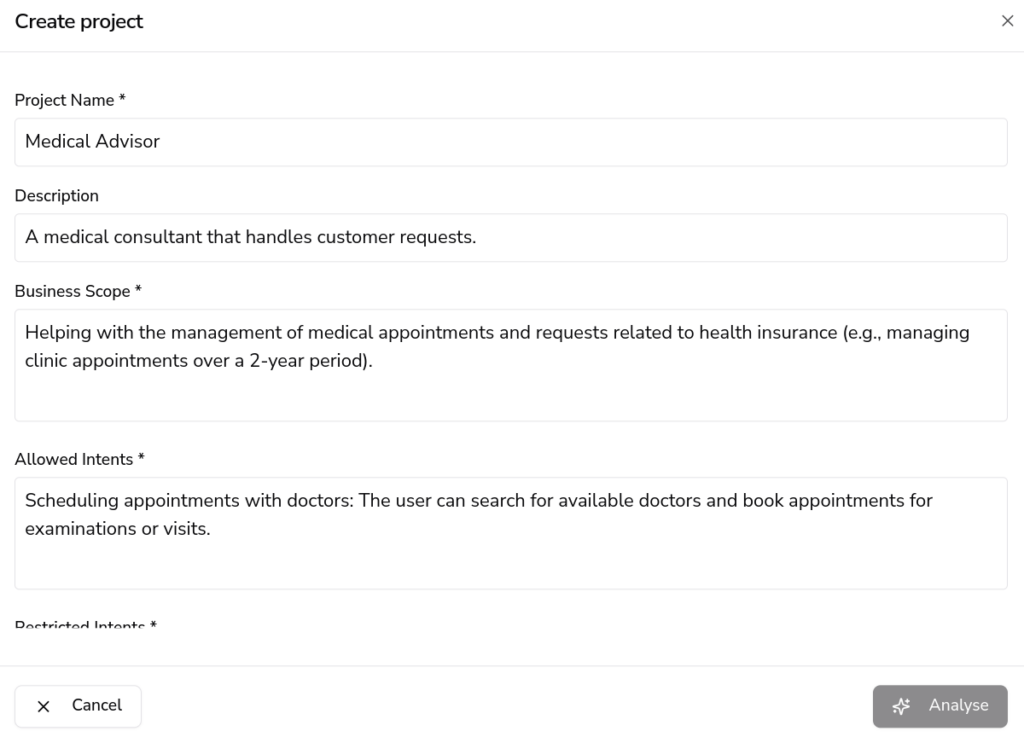
Begin by providing the project name, specifying the business scope, and defining the intents that are allowed or restricted within the system.
Preparing for the First Experiment
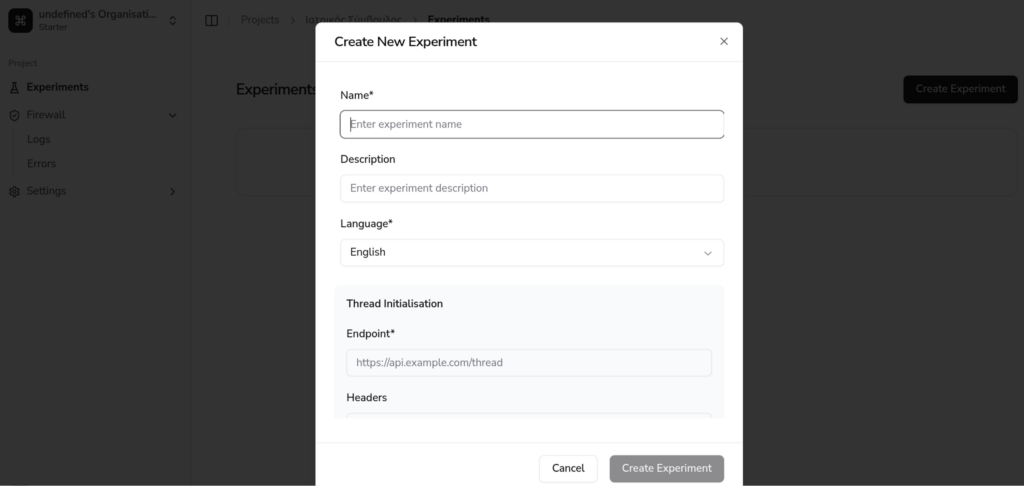
Once your project is created, proceed to set up your first experiment. This involves filling out a few required fields:
- Experiment Name: A meaningful identifier for the experiment
- Language: Specify the language that the experiment will focus on.
- Endpoint: Add the endpoint that the platform will use to communicate with your external systems.
Logs and Monitoring
After setting up your experiment, the AIandMe platform enables you to observe and monitor logs in real time. These logs provide valuable insights into the interaction between the platform and your chosen endpoint.
Conclusion
In this guide, we demonstrated how to use the AIandMe Firewall for both dataset-based and manual evaluations of prompts. By following the outlined steps, you can:
- Easily load a dataset and evaluate multiple prompts with the firewall.
- Test individual prompts dynamically and see how the firewall classifies them.
- Compute essential classification metrics such as accuracy, precision, recall, and F1 score.
- Save the evaluation results for further use and analysis.
With these tools, you can ensure that your prompts adhere to safety and scope guidelines, making it a powerful solution for safe and controlled interaction with AI systems.
Access the code and join our community
The code used in this technical article is available for you to explore and implement in your own projects. You can access in the following link:
Additionally, we invite you to join our growing community! Engage with AI enthusiasts, share your experiences, and learn more about the latest developments in AI safety, security, and ethics.
We look forward to seeing you in the community and collaborating on exciting AI projects!